2024大數據系統架構全解 從知識體系到智能水務應用實戰
在數字化轉型浪潮中,大數據技術已成為驅動行業創新的核心引擎。本文將系統性地闡述2024年最新的大數據開發知識體系,并以“智能水務系統”為藍本,深度解析如何構建一個健壯、高效的大數據應用系統。
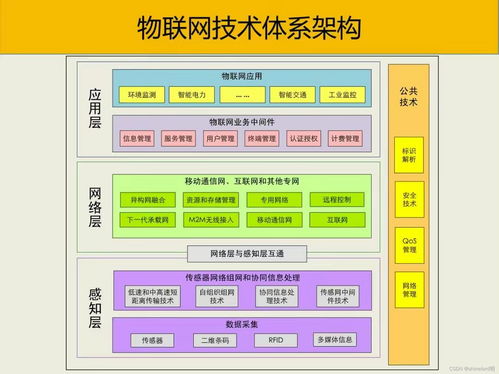
第一部分:2024大數據開發核心知識體系全景
一個完整的大數據知識體系如同金字塔,自底向上包含以下關鍵層級:
- 數據基礎層:
- 數據源與采集: 掌握結構化數據(MySQL, Oracle)、半結構化與非結構化數據(日志、IoT傳感器數據、視頻/圖像)的采集技術,如Flume, Logstash, Kafka, Sqoop等。
- 數據存儲: 深入理解分布式文件系統HDFS、對象存儲(如S3/OSS)、NoSQL數據庫(HBase, Cassandra, MongoDB)與NewSQL數據庫(ClickHouse, TiDB)的選型與應用場景。
- 數據處理與計算層:
- 批處理引擎: 精通Spark Core、Spark SQL(替代傳統Hive進行高效ETL),理解MapReduce原理。
- 流處理引擎: 掌握Flink(當前流批一體的主流選擇)或Spark Streaming,實現低延遲實時計算。
- OLAP引擎: 熟悉Kylin、Druid、ClickHouse等,支撐快速多維分析查詢。
- 數據管理與服務層:
- 數據治理: 涵蓋數據血緣、數據質量、元數據管理(Atlas, Datahub)與主數據管理。
- 任務調度: 熟練使用DolphinScheduler、Airflow進行復雜工作流的編排與監控。
- 數據服務與API化: 通過數據中臺理念,將數據資產封裝為標準化API服務。
- 數據智能與應用層:
- 機器學習/AI框架: 集成Spark MLlib、Flink ML、TensorFlow/PyTorch進行數據挖掘與模型訓練。
- BI與可視化: 使用Superset、FineBI、Tableau等工具實現數據洞察。
- 領域應用開發: 將上述能力與具體業務場景(如智能水務)深度融合。
- 運維與云原生層(2024趨勢):
- 云原生與容器化: 基于Kubernetes部署和管理大數據組件(如使用Spark on K8s),實現彈性伸縮。
- 運維監控: 全鏈路監控體系,涵蓋Metrics(Prometheus)、Logging(ELK)和Tracing(SkyWalking/Jaeger)。
第二部分:構建智能水務大數據系統應用實戰
以“智能水務”為例,我們設計一個從感知到決策的閉環大數據系統。
系統架構設計
- 數據采集層:
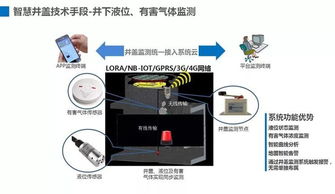
- 物聯網感知數據: 通過MQTT協議接入遍布管網的水壓、流量、水質(pH值、濁度、余氯)傳感器數據,由邊緣網關初步處理后,通過Kafka實時上報至數據平臺。
- 業務系統數據: 從營收系統(用戶繳費)、客服系統(報修工單)、SCADA系統(泵站控制)通過DataX或Canal同步至數據倉庫。
- 外部數據: 集成氣象數據、地理信息(GIS)數據,為分析提供上下文。
- 數據存儲與計算層:
- 實時數據湖: 原始流數據寫入Kafka后,一方面通過Flink進行實時處理(如異常檢測),另一方面持久化到Iceberg/Hudi格式的數據湖中,實現流批存儲統一。
- 數據倉庫: 基于Hive/Spark SQL或云上MaxCompute,構建分層模型(ODS->DWD->DWS->ADS),對清洗后的業務數據進行主題域建模(如客戶主題、管網主題、營收主題)。
- 實時數倉: 利用ClickHouse或Doris,對實時聚合指標(如區域實時供水量、水質超標告警數)進行亞秒級查詢響應。
- 數據處理與分析層:
- 實時處理(Flink作業):
- 泄漏預警: 實時計算管網節點壓力與流量模型,偏差超過閾值即時告警。
- 水質實時監控: 對多指標進行流式關聯分析,快速定位污染源。
- 批量分析(Spark作業):
- 產銷差分析: 每日批量計算供水量與售水量的差值,定位漏損嚴重區域。
- 用戶用水行為畫像: 聚類分析不同類型用戶(居民、工商業)的用水模式,支撐精準服務與需求預測。
- AI模型訓練:
- 用水量預測: 基于歷史用水、天氣、節假日特征,使用時間序列模型(如LSTM)預測未來用水負荷,指導優化調度。
- 管網健康度評估: 利用圖算法與歷史維修數據,構建管網脆弱性預測模型。
- 數據服務與應用層:
- 統一數據服務網關: 將分析結果(如預測結果、聚合指標、用戶畫像標簽)通過API對外提供服務。
- 核心應用場景:
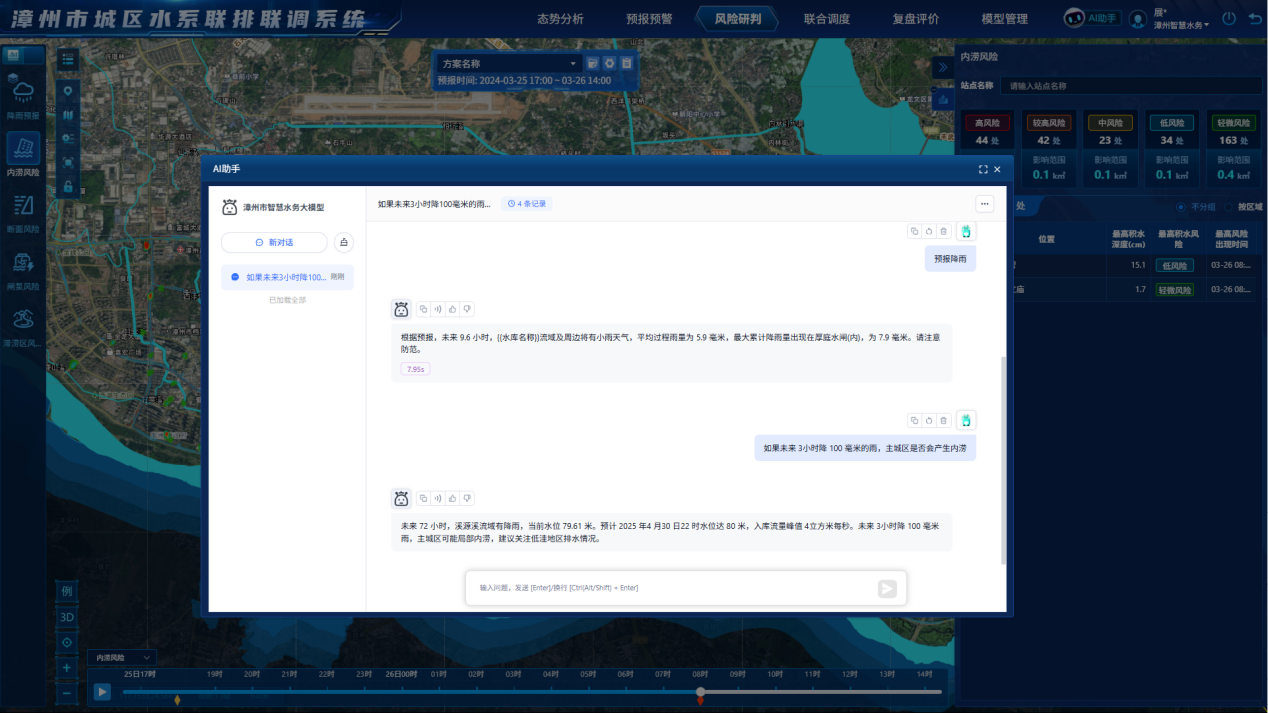
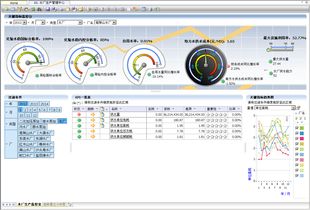
- 調度中心指揮大屏: 基于GIS的可視化大屏,實時展示全網壓力、流量、水質及告警信息。
- 移動巡檢APP: 向巡檢人員推送預警工單、最優巡檢路徑及歷史數據。
- 智慧客服系統: 當用戶來電時,自動彈出該區域的停水計劃、水質報告及用戶畫像,提升服務體驗。
- 輔助決策報告: 自動生成周期性運營報告,如漏損率分析報告、能耗分析報告。
- 平臺保障層:
- 資源管理與調度: 基于YARN或Kubernetes,實現計算資源的彈性分配。
- 安全與權限: 使用Ranger或Sentry進行庫、表、列級別的數據權限控制,審計所有數據訪問行為。
- 元數據與數據質量: 建立端到端的數據血緣,對關鍵業務指標(如每日供水量)設置質量校驗規則并實時監控。
關鍵挑戰與應對
- 數據質量: 傳感器數據存在噪聲與缺失,需在流處理環節引入濾波、插值等數據修復算法。
- 實時性與準確性平衡: 泄漏檢測模型需在低延遲與高準確率間取得平衡,可采用“流式粗判+批量精核”的混合模式。
- 系統復雜度: 采用微服務架構解耦各子系統,并通過統一的數據平臺降低煙囪式開發。
###
構建現代大數據系統,已從單純的技術堆砌轉向以價值為導向的體系化設計。2024年的開發者,需在夯實流批一體、數據湖倉、云原生等核心技術的深刻理解業務領域,如智能水務中的管網物理特性和水務運營知識。唯有如此,才能設計出數據驅動、持續演進、真正創造業務價值的大數據系統架構。本文提供的知識體系與實戰案例,旨在為這一旅程提供一份系統性的路線圖。
如若轉載,請注明出處:http://www.bonchef.cn/product/29.html
更新時間:2026-06-06 17:49:51